
“在现实中无法飞翔的人在梦中飞翔。”
🐎 跑马场
💾 数据库

笔者在此想再次强调,即便是原创电子小说游戏的场景,原本也是由多种数据组合而成的。表层看起来是一个画面或故事,在深层只不过是无意义的片段集合。同样的剧情文字或画面,根据玩家的操作被赋予了许多不同的功能。如果是这样的话,将这些片段用其他方式进行组合,或许能够制作出与原作具有相同价值的另一种版本的电子小说游戏,这样的想法完全是一种自然趋势。Mad Movie 的制作者们为了用别样的组合再次实现与原作相遇时的感动,充满热情地解析系统,再编辑数据。至少从他们的认知层面来看,这种行为与剽窃、戏仿或采样等有着根本不同的创作意识。
——东浩纪《动物化的后现代》
当代的读者可能对十九世纪小说中细节的连篇累牍感觉不耐烦,其实,当时有的小说家也觉得不满意,他们发现,小说近乎变态的细节呈现,很可能只是从照相术里进行了机械的偷师。夏洛蒂·勃朗特就觉得简·奥斯丁所写的东西毫不生动,就像一张“银版摄影法”(daguerro-typed)所照出来的东西。
——张秋子《堂吉诃德的眼镜》
“我本来就是由海量的 youtube 影像、三分钟简介电影、维基百科、脸书短废文、某某说历史上的君士坦丁围城战、太平洋海战、诺曼底登陆、三分钟理解相对论、NBA 史上最伟大的五十个灌篮、洛克菲勒家族的艺术藏品、大英博物馆导览影像……再乘以百万倍的各种讯息构成”。这样的“我”,可能和二〇〇四过世的我的父亲,剧烈(如远古大陆的陆块分裂漂流)跳跃、分离成“不同的人类”,而更接近之前科幻电影中描述的,可能会叛变的仆佣角色,机器人。
——骆以军《明朝》
“电子女孩”(e-girl)这个点很重要。许多受访者声称甚至不知道任何现实中色情影星的名字。他们对电子女孩更感兴趣。在撸虫界,这个词主要指那些走“游戏少女”风格的女性——霓虹色的头发、猫耳朵、蜘蛛侠紧身衣——她们通常在 OnlyFans 上售卖成人内容。OnlyFans 革命带来的色情内容数量之巨令人咋舌。对比 2005 年专业色情业发布的 1.3 万部影片,以及去年 OnlyFans 上 460 万名注册创作者,你就能理解今天色情成瘾者的困境:值得撸的东西实在太多了。PMV 将这些素材中最精彩的部分融合进超速、有节奏的高光剪辑中,是对这种泛滥的逻辑回应。
身在阿姆斯特丹的 NoodleDude 对自己的成就很谦虚。他认为 PMV 艺术就像早期的嘻哈音乐,是将现有的素材扭曲成全新的形状。他意识到自己和同僚是在利用他人的劳动获利,而且也被一些愤怒的邮件和法律威胁吓到了,所以 NoodleDude 最近开始给出现在视频中的每一位女性署名。
——Daniel Kolitz《The Goon Squad》
💡 闪念集

我记得无影山路面的井盖常常冒出暖气。
小学班车的档把下面是与外面连通的。
所以有一次,蒸汽涌入了车里。
“播客和广播节目的区别是什么?”
我给一个,播客从业者往往以创作者自居,后者是上班。
编剧不仁,以角色为刍狗。
🛠️ 操作台
🎟️ 电影票

这是我用 Google AI Studio 做的第一个小应用1,直接把几张成品发在了小红书上,也没写什么甜腻的文字,还有些受欢迎,完全是(情理之中)意料之外。
有人在评论区要提示词,不过因为我没有使用经验,这个应用也是一轮一轮聊出来的,所以很难提供现成的提示词。比较完整的过程上周已经发了博文:保管时间:Google AI Studio 自制电影票根(创作谈?)。
电影对我来说不是必需品,但这变成了重新开始看电影的一个契机,这部分才算这个小项目的价值吧。
另外,博文的附录(怎么还有这种东西)里写了用 Nano Banana Pro 批注网页用法的提示词。但我没讲这段提示词的原版是我在即刻看到的(博主“歸藏”),恶意满满,我算是“铸剑为犁”了。
原版大概是这样:
1 | 生成图片,把它打印出来,然后用红墨水疯狂地加上手写中文批注、涂鸦、乱画,如果你想的话,检索这个账户内容,涂鸦的内容主要为吐槽他,还可以加点小剪贴画。 |
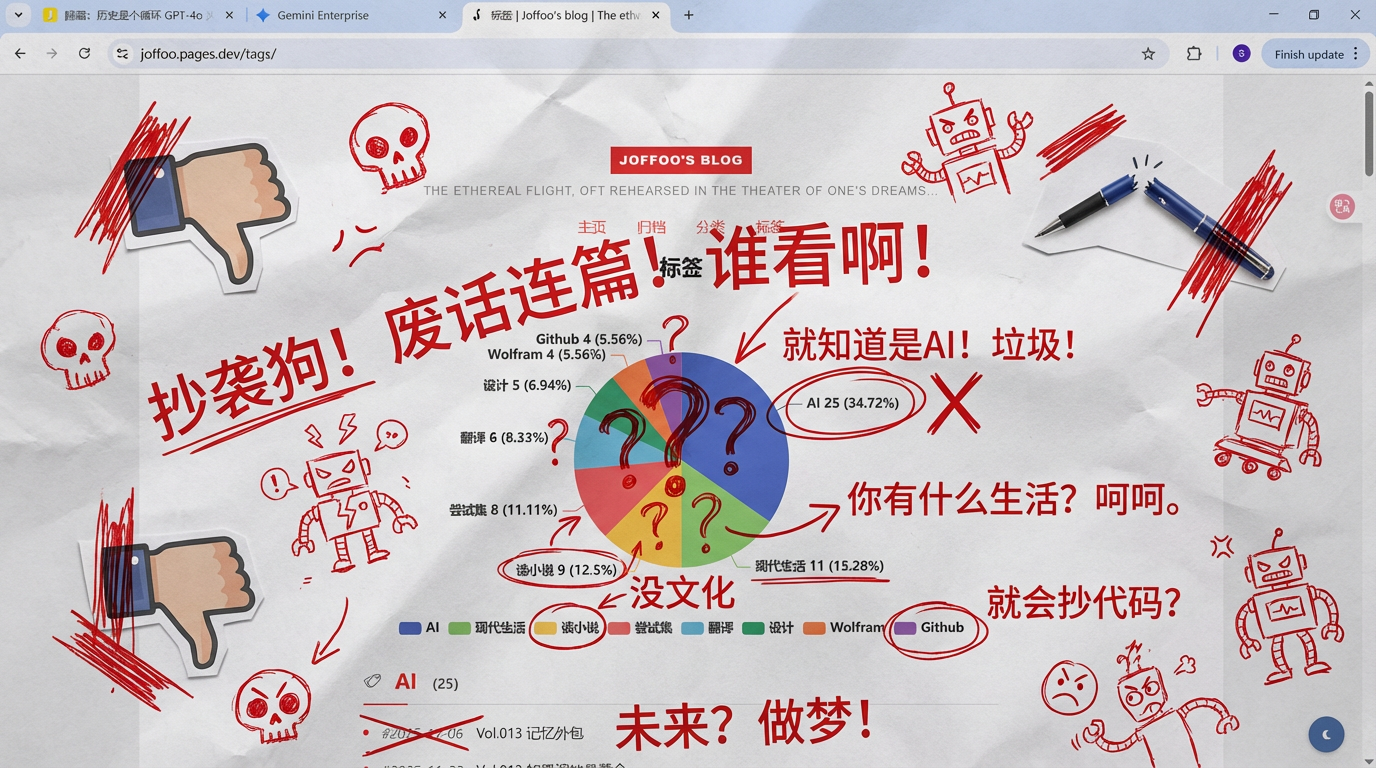
我看完之后非常开心,乐不打一处来,于是邀请另一位同学加入战斗:
1 | 一把夺过这张纸,然后用蓝色墨水疯狂地加上手写中文批注、涂鸦、乱画,涂鸦的内容主要为反驳红色墨水的内容,还可以加点小剪贴画。 |

1 | 红墨水继续反驳蓝墨水,疯狂地加上手写中文批注、涂鸦、乱画,**最后一气之下把纸撕了** |

🔍 OCR(续)

文字任务的完成度往往难以衡量,不妨从 OCR 这个维度看一下 Gemini 3.0 系列模型的进步程度。
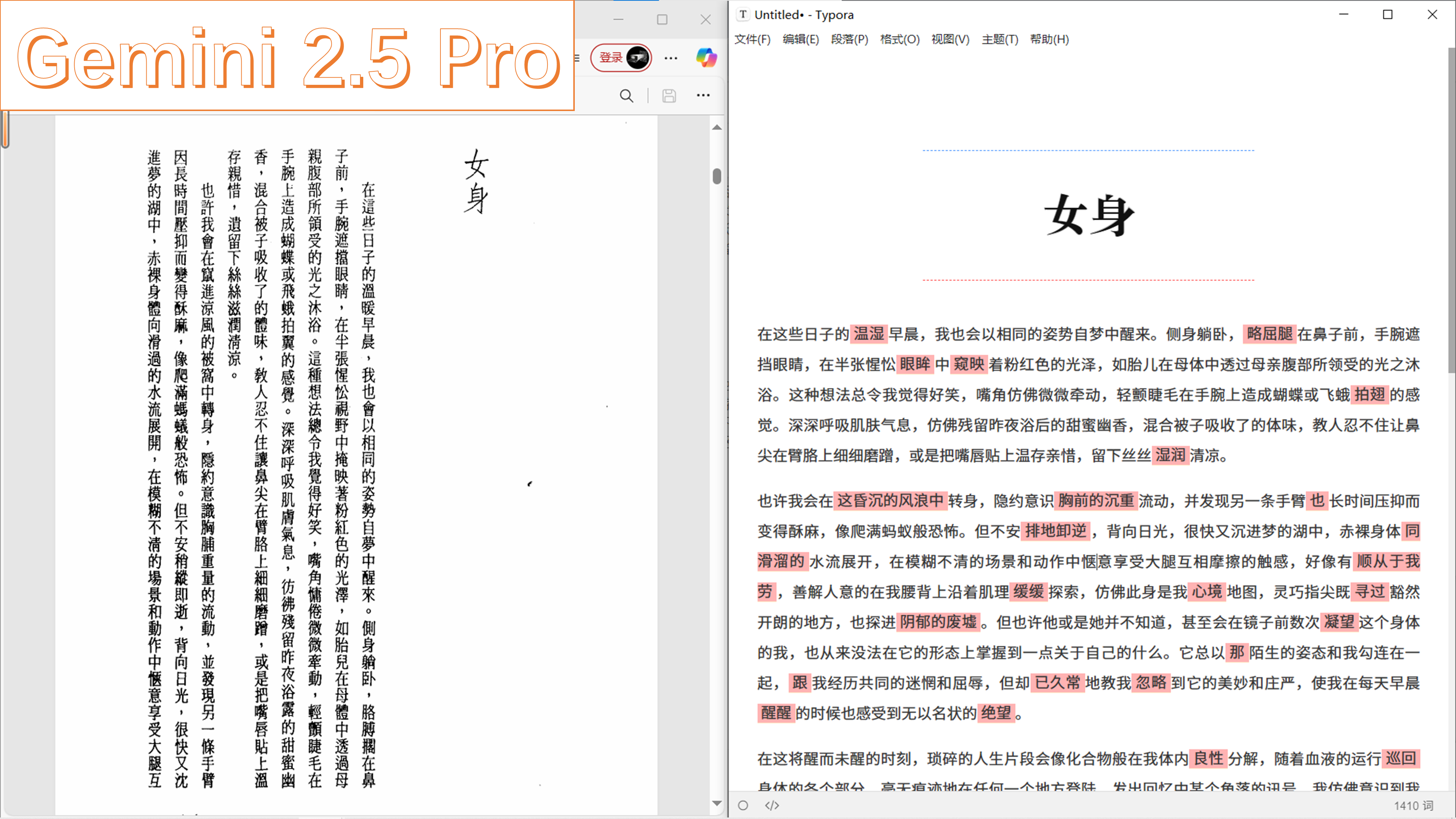
实验材料仍是《光学字符识别?也学点新的》一篇中(写于今年九月份)采用的扫描版繁体竖排 PDF,董启章的小说《双身》。之前使用 Gemini 2.5 Pro 模型的识别效果如下,可见,非常一般。如果读到这样的文本,大概只是读到了原作的 2/3,自己可能还发现不了问题。
再用一下新出的 Gemini 3.0 Flash 试试,只有少许“怪词”(“窜进”应该不算怪)会出错,进步已经相当明显。

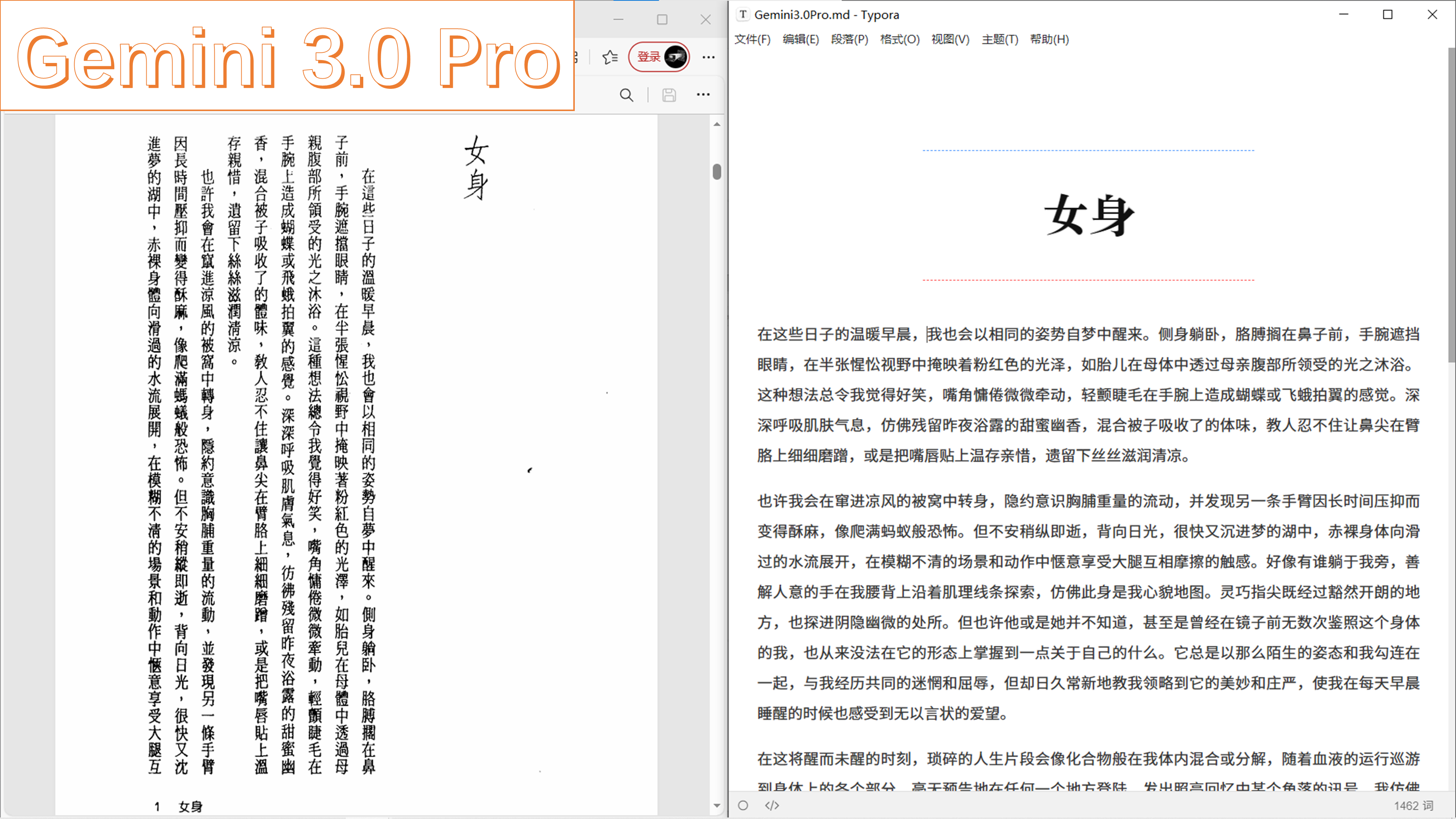
如果用最为珍贵的 Gemini 3.0 Pro 的话,在我目力所及的范围内没有错字了。也就是说,Gemini 3.0 Pro 真正达到了“我的可读标准”,读它的识别结果和我自己读 PDF 等效。
另外,对于“贯口式”文本也不会突然卡住了(材料是董启章《繁胜录》的“街之城市”一节):

作为时隔三个多月的一次跟进。
补充:
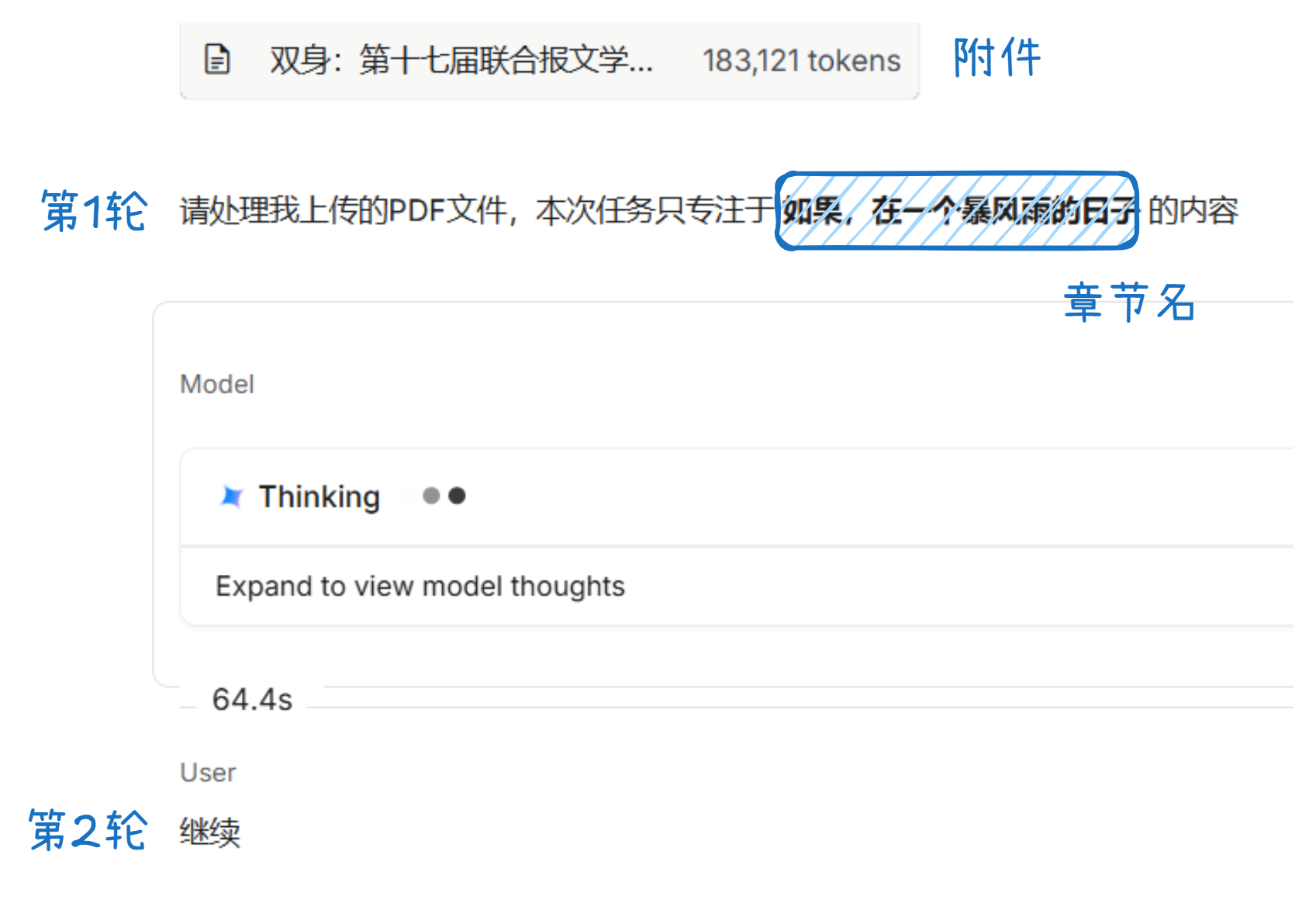
如果你 OCR 的文本经常被 block 的话(比如《双身》),就多次修改第一轮对话的提示词,每次运行前更换不同章节名。不知为何,第一轮基本可以完整输出(如果还是被 block,就在第二轮说“继续”,两轮输出结果加在一起一般就是完整的)。
这样操作的另一个优势是,之前识别的内容不会干扰模型的发挥。
具体提示词还是参考:光学字符识别?也学点新的。
🎭 大喜利(续)

“何必用生图模型生成文字”的疑问依然萦绕心头,于是仿照《保管时间:Google AI Studio 自制电影票根》的思路,用 Google AI Studio 生成一个网页应用2。
思路比上次还要简单:用户上传图片 -> 调用思考模型吐槽(用之前的提示词) -> 把吐槽内容以字幕形式显示在图像上(字幕格式也参考之前的提示词)。
除此之外,稍微加几个功能:
- 剪贴板粘贴
- Gemini 3.0 Pro 和 Gemini 2.5 Pro 的模型切换
- 字幕自适应显示,不能因为话多就显示不全
- 出错之后加一个重试按钮
由于不涉及版式微调,每个功能基本一遍过。
页面大概是这样的(两次结果拼在一起了,还因为是截图所以比较模糊):
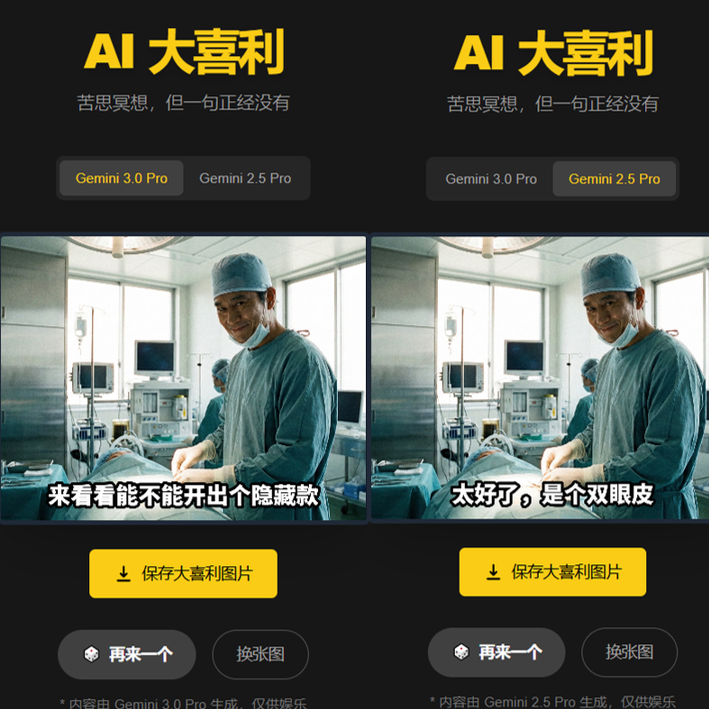
因为模型没有改变,幽默感相比于之前的版本也并无本质提升,只放一张新图作为参考吧:

调用了思考模型,却不呈现思考过程,于是运行时间会显得很长。但长时间冥思苦想的结果却是一句怪话,这本身就是一种幽默的行径吧。
1. https://ai.studio/apps/drive/1vnBFXRj8PIAxnJQAGIq-Gcv0e-Hlf0BP ↩
2. https://ai.studio/apps/drive/1wH_djy0Hsd4T77wYKggehYIdoTSC-cit ↩
